github.com/spencermountain/compromise @14.15.1 sqlite
README

compromise

modest natural language processing
npm install compromise
<sub>
by
<a href="https://spencermounta.in/">Spencer Kelly</a> and
<a href="https://github.com/spencermountain/compromise/graphs/contributors">
many contributors
</a>
</sub>
<a href="https://npmjs.org/package/compromise">
<img src="https://img.shields.io/npm/v/compromise.svg?style=flat-square" />
![]()

<sub>
<a href="https://github.com/nlp-compromise/fr-compromise">french</a> • <a href="https://github.com/nlp-compromise/de-compromise">german</a> • <a href="https://github.com/nlp-compromise/it-compromise">italian</a> • <a href="https://github.com/nlp-compromise/es-compromise">spanish</a>
</sub>
don't you find it strange,
how easy text is to make,
↬ᔐᖜ↬
and how hard it is to actually parse and use?
compromise tries its best to turn text into data.
it makes limited and sensible decisions.
it's not as smart as you'd think.
import nlp from 'compromise'
let doc = nlp('she sells seashells by the seashore.')
doc.verbs().toPastTense()
doc.text()
// 'she sold seashells by the seashore.'
don't be fancy, at all:
if (doc.has('simon says #Verb')) {
return true
}
grab parts of the text:
let doc = nlp(entireNovel)
doc.match('the #Adjective of times').text()
// "the blurst of times?"
and get data:
import plg from 'compromise-speech'
nlp.extend(plg)
let doc = nlp('Milwaukee has certainly had its share of visitors..')
doc.compute('syllables')
doc.places().json()
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/
avoid the problems of brittle parsers:
let doc = nlp("we're not gonna take it..")
doc.has('gonna') // true
doc.has('going to') // true (implicit)
// transform
doc.contractions().expand()
doc.text()
// 'we are not going to take it..'
![]()
and whip stuff around like it's data:
let doc = nlp('ninety five thousand and fifty two')
doc.numbers().add(20)
doc.text()
// 'ninety five thousand and seventy two'
![]()
-because it actually is-
let doc = nlp('the purple dinosaur')
doc.nouns().toPlural()
doc.text()
// 'the purple dinosaurs'

Use it on the client-side:
<script src="https://unpkg.com/compromise"></script>
<script>
var doc = nlp('two bottles of beer')
doc.numbers().minus(1)
document.body.innerHTML = doc.text()
// 'one bottle of beer'
</script>
or likewise:
import nlp from 'compromise'
var doc = nlp('London is calling')
doc.verbs().toNegative()
// 'London is not calling'
![]()
compromise is ~250kb (minified):

it's pretty fast. It can run on keypress:

it works mainly by conjugating all forms of a basic word list.
The final lexicon is ~14,000 words:
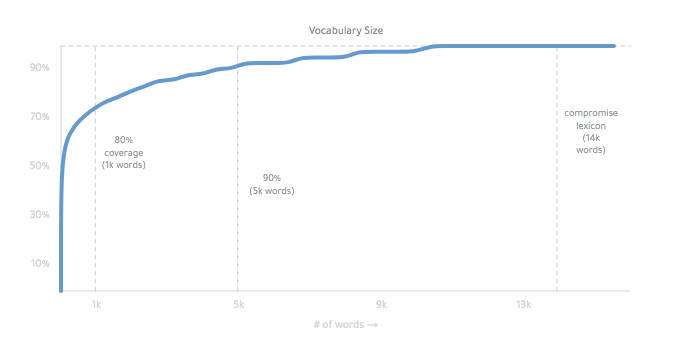
you can read more about how it works, here. it's weird.
okay -
compromise/one
A tokenizer of words, sentences, and punctuation.
import nlp from 'compromise/one'
let doc = nlp("Wayne's World, party time")
let data = doc.json()
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/
compromise/one splits your text up, wraps it in a handy API,
-
and does nothing else -
/one is quick - most sentences take a 10th of a millisecond.
It can do ~1mb of text a second - or 10 wikipedia pages.
Infinite jest takes 3s.
You can also parallelize, or stream text to it with compromise-speed.
compromise/two
A part-of-speech tagger, and grammar-interpreter.
import nlp from 'compromise/two'
let doc = nlp("Wayne's World, party time")
let str = doc.match('#Possessive #Noun').text()
// "Wayne's World"
compromise/two automatically calculates the very basic grammar of each word.
this is more useful than people sometimes realize.
Light grammar helps you write cleaner templates, and get closer to the information.
compromise has 83 tags, arranged in a handsome graph.
#FirstName → #Person → #ProperNoun → #Noun
you can see the grammar of each word by running doc.debug()
you can see the reasoning for each tag with nlp.verbose('tagger').
if you prefer Penn tags, you can derive them with:
let doc = nlp('welcome thrillho')
doc.compute('penn')
doc.json()
compromise/three
Phrase and sentence tooling.
import nlp from 'compromise/three'
let doc = nlp("Wayne's World, party time")
let str = doc.people().normalize().text()
// "wayne"
compromise/three is a set of tooling to zoom into and operate on parts of a text.
.numbers() grabs all the numbers in a document, for example - and extends it with new methods, like .subtract().
When you have a phrase, or group of words, you can see additional metadata about it with .json()
let doc = nlp('four out of five dentists')
console.log(doc.fractions().json())
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/
let doc = nlp('$4.09CAD')
doc.money().json()
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
<img height="80px" src="https://use
Extension points exported contracts — how you extend this code
DateView (Interface)Core symbols most depended-on inside this repo
hasShape
Languages
Modules by API surface
Used by 4 indexed graphs manifest dependencies, hub-wide
Dependencies from manifests, versioned
For agents
$ claude mcp add compromise \
-- python -m otcore.mcp_server <graph>