github.com/shibing624/MedicalGPT @2.7.0 sqlite
README
🇨🇳中文 | 🌐English | 📖文档/Docs | 🤖模型/Models
![]()
MedicalGPT: Training Medical GPT Model
![]()
![]()
![]()

![]()
📖 Introduction
MedicalGPT trains a medical large language model using the ChatGPT training pipeline, implementing pretraining, supervised finetuning, RLHF (Reward Modeling and Reinforcement Learning), and DPO (Direct Preference Optimization).
MedicalGPT trains medical large models, implementing incremental pretraining, supervised fine-tuning, RLHF (reward modeling, reinforcement learning training), and DPO (direct preference optimization).

- The RLHF training pipeline is from Andrej Karpathy's presentation PDF State of GPT, video Video
- The DPO method is from the paper Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- The ORPO method is from the paper ORPO: Monolithic Preference Optimization without Reference Model

Training MedicalGPT model:
- Stage 1:PT(Continue PreTraining), Pre-training the LLaMA model on massive domain document data to inject domain knowledge
- Stage 2: SFT (Supervised Fine-tuning) has supervised fine-tuning, constructs instruction fine-tuning data sets, and performs instruction fine-tuning on the basis of pre-trained models to align instruction intentions
- Stage 3: RM (Reward Model) reward model modeling, constructing a human preference ranking data set, training the reward model to align human preferences, mainly the "HHH" principle, specifically "helpful, honest, harmless"
- Stage 4: RL (Reinforcement Learning) is based on human feedback reinforcement learning (RLHF), using the reward model to train the SFT model, and the generation model uses rewards or penalties to update its strategy in order to generate higher quality, more in line with human preferences text
- Stage 5: Agent Finetuning, support Agent function call formatting with
--tool_formatargument during SFT stage. We support various models like Qwen, Mistral, LLaMA3, GLM4 and more.
▶️ Demo
- Hugging Face Demo: doing
We provide a simple Gradio-based interactive web interface. After the service is started, it can be accessed through a browser, enter a question, and the model will return an answer. The command is as follows:
python demo/gradio_demo.py --base_model path_to_llama_hf_dir --lora_model path_to_lora_dir
Parameter Description:
--base_model {base_model}: directory to store LLaMA model weights and configuration files in HF format, or use the HF Model Hub model call name--lora_model {lora_model}: The directory where the LoRA file is located, and the name of the HF Model Hub model can also be used. If the lora weights have been merged into the pre-trained model, delete the --lora_model parameter--tokenizer_path {tokenizer_path}: Store the directory corresponding to the tokenizer. If this parameter is not provided, its default value is the same as --lora_model; if the --lora_model parameter is not provided, its default value is the same as --base_model--use_cpu: use only CPU for inference--gpus {gpu_ids}: Specifies the number of GPU devices used, the default is 0. If using multiple GPUs, separate them with commas, such as 0,1,2
📁 Project Structure
MedicalGPT/
├── training/ # Core training scripts (main learning path)
│ ├── template.py # Conversation template definitions
│ ├── pretraining.py # Stage 1: Continue Pretraining (PT)
│ ├── supervised_finetuning.py # Stage 2: Supervised Fine-tuning (SFT)
│ ├── reward_modeling.py # Stage 3: Reward Modeling (RM)
│ ├── ppo_training.py # Stage 3: Reinforcement Learning (PPO/RLOO)
│ ├── dpo_training.py # Stage 3: Direct Preference Optimization (DPO)
│ ├── orpo_training.py # Stage 3: ORPO
│ └── grpo_training.py # Stage 3: GRPO
│
├── scripts/ # One-click run scripts + DeepSpeed configs
│ ├── run_pt.sh / run_sft.sh / run_dpo.sh / ...
│ └── zero1.json / zero2.json / zero3.json
│
├── demo/ # Inference, deployment & application examples
│ ├── inference.py / gradio_demo.py / fastapi_server_demo.py
│ ├── openai_api.py / chatpdf.py
│ └── inference_multigpu_demo.py
│
├── tools/ # Model merging, quantization & data processing
│ ├── merge_peft_adapter.py / merge_tokenizers.py
│ ├── model_quant.py / eval_quantize.py
│ └── convert_dataset.py / validate_jsonl.py
│
├── notebooks/ # Colab tutorial notebooks
│ ├── run_training_dpo_pipeline.ipynb
│ └── run_training_ppo_pipeline.ipynb
│
├── data/ # Training data
├── docs/ # Documentation
└── tests/ # Tests
| Directory | Description | Target Audience |
|---|---|---|
training/ |
Core training code covering PT→SFT→RM→PPO/DPO/ORPO/GRPO pipeline | Developers learning training principles |
scripts/ |
One-click run scripts and DeepSpeed configs, copy and use | Users who want to start training quickly |
demo/ |
Inference, Gradio UI, FastAPI server, RAG QA examples | Users who want to deploy and try models |
tools/ |
LoRA merging, quantization, vocab extension, data conversion | Users needing model post-processing |
notebooks/ |
End-to-end Colab tutorials, one-click run | Beginners for quick hands-on experience |
All scripts are run from the project root, e.g.:
bash scripts/run_sft.sh
🚀 Training Pipeline
Stage 1: Continue Pretraining
Based on the llama-7b model, use medical encyclopedia data to continue pre-training, and expect to inject medical knowledge into the pre-training model to obtain the llama-7b-pt model. This step is optional
bash scripts/run_pt.sh
Stage 2: Supervised FineTuning
Based on the llama-7b-pt model, the llama-7b-sft model is obtained by using medical question-and-answer data for supervised fine-tuning. This step is required
Supervised fine-tuning of the base llama-7b-pt model to create llama-7b-sft
bash scripts/run_sft.sh
Stage 3: Reward Modeling
RM(Reward Model): reward model modeling
In principle, we can directly use human annotations to fine-tune the model with RLHF.
However, this will require us to send some samples to humans to be scored after each round of optimization. This is expensive and slow due to the large number of training samples required for convergence and the limited speed at which humans can read and annotate them. A better strategy than direct feedback is to train a reward model RM on the human annotated set before entering the RL loop. The purpose of the reward model is to simulate human scoring of text.
The best practice for building a reward model is to rank the prediction results, that is, for each prompt (input text) corresponding to two results (yk, yj), the model predicts which score the human annotation is higher. The RM model is trained by manually marking the scoring results of the SFT model. The purpose is to replace manual scoring. It is essentially a regression model used to align human preferences, mainly based on the "HHH" principle, specifically "helpful, honest, harmless".
Based on the llama-7b-sft model, the reward preference model is trained using medical question and answer preference data, and the llama-7b-reward model is obtained after training. This step is required
Reward modeling using dialog pairs from the reward dataset using the llama-7b-sft to create llama-7b-reward:
bash scripts/run_rm.sh
Stage 4: Reinforcement Learning
The purpose of the RL (Reinforcement Learning) model is to maximize the output of the reward model. Based on the above steps, we have a fine-tuned language model (llama-7b-sft) and reward model (llama-7b-reward). The RL loop is ready to execute.
This process is roughly divided into three steps:
- Enter prompt, the model generates a reply
- Use a reward model to score responses
- Based on the score, a round of reinforcement learning for policy optimization (PPO)
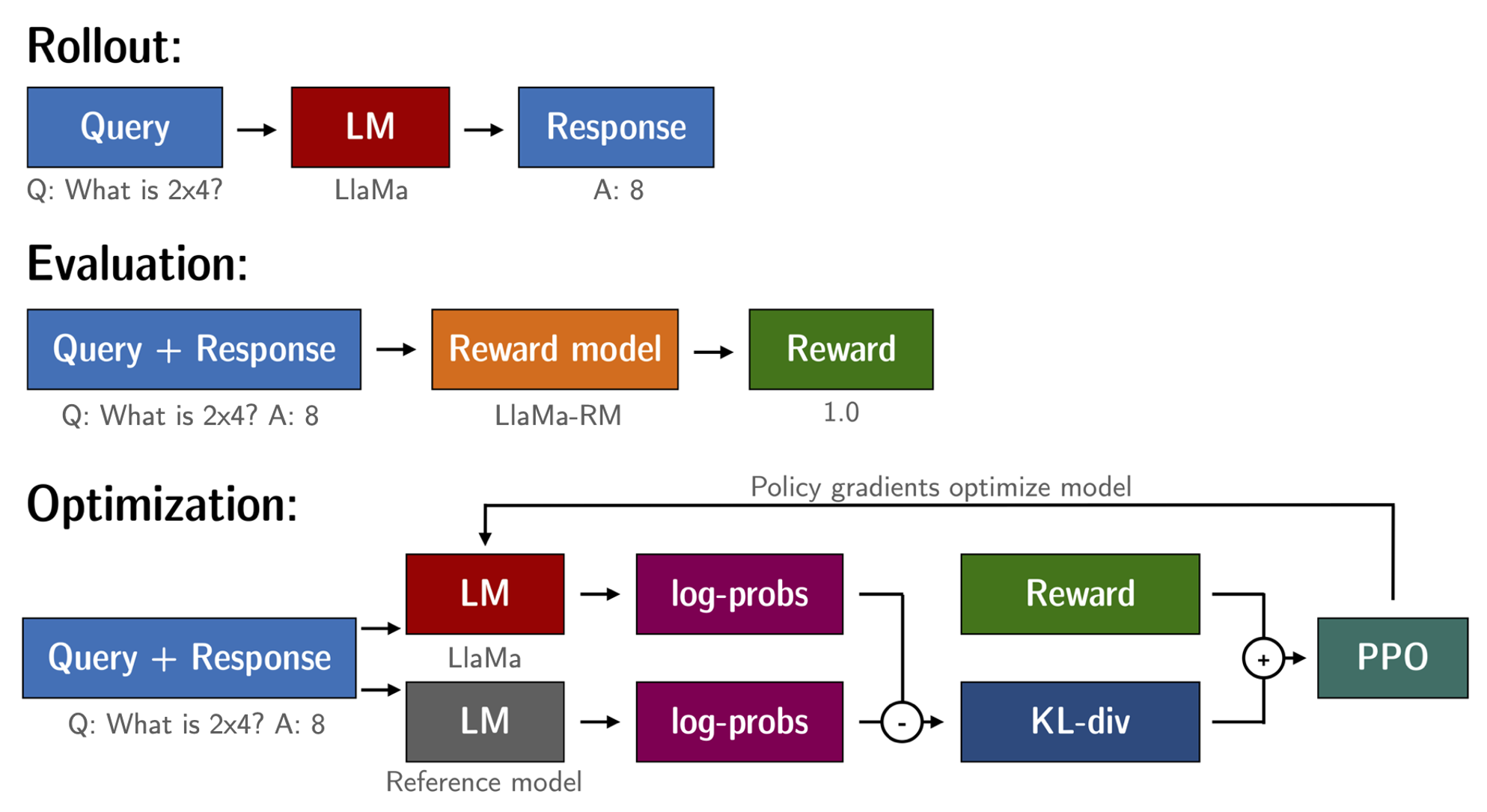
Reinforcement Learning fine-tuning of llama-7b-sft with the llama-7b-reward reward model to create llama-7b-rl
bash scripts/run_ppo.sh
Supported Models
| Model Name | Model Size | Target Modules | Template |
|---|---|---|---|
| Baichuan | 7B/13B | W_pack | baichuan |
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | vicuna |
| ChatGLM | 6B | query_key_value | chatglm |
| ChatGLM2 | 6B | query_key_value | chatglm2 |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| Cohere | 104B | q_proj,v_proj | cohere |
| DeepSeek | 7B/16B/67B | q_proj,v_proj | deepseek |
| DeepSeek3 | 671B | q_proj,v_proj | deepseek3 |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | alpaca |
| LLaMA2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| LLaMA3 | 8B/70B | q_proj,v_proj | llama3 |
| Mistral | 7B/8x7B | q_proj,v_proj | mistral |
| Orion | 14B | q_proj,v_proj | orion |
| Qwen | 1.8B/7B/14B/72B | c_attn | chatml |
| Qwen1.5 | 0.5B/1.8B/4B/14B/72B | q_proj,v_proj | qwen |
| Qwen2.5 | 0.5B/1.8B/4B/14B/72B | q_proj,v_proj | qwen |
| Qwen3 | 0.6B/1.7B/4B/8B/14B/32B/235B | q_proj,v_proj | qwen3 |
| Qwen3.5 | 0.8B/2B/4B/9B/27B/35B/122B | q_proj,v_proj | qwen3_5 |
| XVERSE | 13B | query_key_value | xverse |
| Yi | 6B/34B | q_proj,v_proj | yi |
💾 Install
Updating the requirements
From time to time, the requirements.txt changes. To update, use this command:
git clone https://github.com/shibing624/MedicalGPT
cd MedicalGPT
pip install -r requirements.txt --upgrade
Hardware Requirement (VRAM)
| Train Method | Bits | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| LoRA | 1 |
Core symbols most depended-on inside this repo
register_conv_templateShape
Languages
Modules by API surface
Dependencies from manifests, versioned
For agents
$ claude mcp add MedicalGPT \
-- python -m otcore.mcp_server <graph>