hub / github.com/promptslab/Awesome-Prompt-Engineering
github.com/promptslab/Awesome-Prompt-Engineering @main
74 symbols
188 edges
38 files
4 documented · 5%
README
Awesome Prompt Engineering 🧙♂️
A hand-curated collection of resources for Prompt Engineering and Context Engineering — covering papers, tools, models, APIs, benchmarks, courses, and communities for working with Large Language Models.
https://promptslab.github.io
```
Master Prompt Engineering. Join the Course at https://promptslab.github.io
```




 ---
## 🚀 Start Here
New to prompt engineering? Follow this path:
---
## 🚀 Start Here
New to prompt engineering? Follow this path:
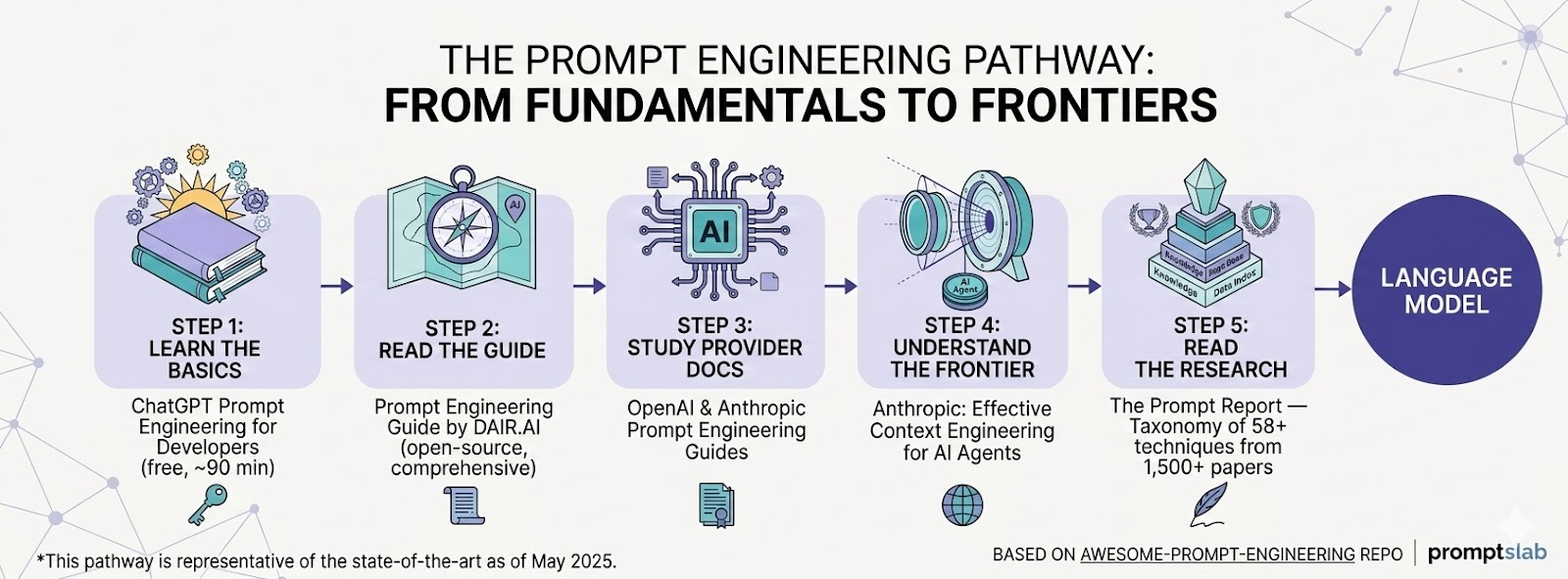 1. **Learn the basics** → [ChatGPT Prompt Engineering for Developers](https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/) (free, ~90 min)
2. **Read the guide** → [Prompt Engineering Guide by DAIR.AI](https://www.promptingguide.ai/) (open-source, comprehensive)
3. **Study provider docs** → [OpenAI Prompt Engineering Guide](https://platform.openai.com/docs/guides/prompt-engineering) · [Anthropic Prompt Engineering Guide](https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview)
4. **Understand where the field is heading** → [Anthropic: Effective Context Engineering for AI Agents](https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents)
5. **Read the research** → [The Prompt Report](https://arxiv.org/abs/2406.06608) — taxonomy of 58+ prompting techniques from 1,500+ papers
---
## Table of Contents
- [Papers](#papers)
- [Major Surveys](#major-surveys)
- [Prompt Optimization and Automatic Prompting](#prompt-optimization-and-automatic-prompting)
- [Prompt Compression](#prompt-compression)
- [Reasoning Advances](#reasoning-advances)
- [In-Context Learning](#in-context-learning)
- [Agentic Prompting and Multi-Agent Systems](#agentic-prompting-and-multi-agent-systems)
- [Multimodal Prompting](#multimodal-prompting)
- [Structured Output and Format Control](#structured-output-and-format-control)
- [Prompt Injection and Security](#prompt-injection-and-security)
- [Applications of Prompt Engineering](#applications-of-prompt-engineering)
- [Text-to-Image Generation](#text-to-image-generation)
- [Text-to-Music/Audio Generation](#text-to-musicaudio-generation)
- [Foundational Papers (Pre-2024)](#foundational-papers-pre-2024)
- [Tools and Code](#tools-and-code)
- [Prompt Management and Testing](#prompt-management-and-testing)
- [LLM Evaluation Tools](#llm-evaluation-tools)
- [Agent Frameworks](#agent-frameworks)
- [Prompt Optimization Tools](#prompt-optimization-tools)
- [Red Teaming and Prompt Security](#red-teaming-and-prompt-security)
- [MCP (Model Context Protocol)](#mcp-model-context-protocol)
- [Vibe Coding and AI Coding Assistants](#vibe-coding-and-ai-coding-assistants)
- [CLI-Based Coding Agents](#cli-based-coding-agents)
- [AI Code Editors / IDEs](#ai-code-editors--ides)
- [IDE Extensions / Plugins](#ide-extensions--plugins)
- [AI Coding Platforms / Cloud Agents](#ai-coding-platforms--cloud-agents)
- [Open-Source Coding Agent Frameworks](#open-source-coding-agent-frameworks)
- [Other Notable Repositories](#other-notable-repositories)
- [APIs](#apis)
- [Datasets and Benchmarks](#datasets-and-benchmarks)
- [Models](#models)
- [AI Content Detectors](#ai-content-detectors)
- [Books](#books)
- [Courses](#courses)
- [Tutorials and Guides](#tutorials-and-guides)
- [Videos](#videos)
- [Communities](#communities)
- [Autonomous Research & Self-Improving Agents](#autonomous-research--self-improving-agents)
- [How to Contribute](#how-to-contribute)
---
## Papers
📄
### Major Surveys
- [The Prompt Report: A Systematic Survey of Prompting Techniques](https://arxiv.org/abs/2406.06608) [2024] — Most comprehensive survey: taxonomy of 58 text and 40 multimodal prompting techniques from 1,500+ papers. Co-authored with OpenAI, Microsoft, Google, Stanford.
- [A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications](https://arxiv.org/abs/2402.07927) [2024] — 44 techniques across application areas with per-task performance summaries.
- [A Survey of Prompt Engineering Methods in LLMs for Different NLP Tasks](https://arxiv.org/abs/2407.12994) [2024] — 39 prompting methods across 29 NLP tasks.
- [A Survey of Automatic Prompt Engineering: An Optimization Perspective](https://arxiv.org/abs/2502.11560) [2025] — Formalizes auto-PE methods as discrete/continuous/hybrid optimization problems.
- [Efficient Prompting Methods for Large Language Models: A Survey](https://arxiv.org/abs/2404.01077) [2024] — Survey of efficiency-oriented prompting (compression, optimization, APE) for reducing compute and latency.
- [Navigate through Enigmatic Labyrinth: A Survey of Chain of Thought Reasoning](https://arxiv.org/abs/2309.15402) [2023, ACL 2024] — Systematic CoT survey.
- [Demystifying Chains, Trees, and Graphs of Thoughts](https://arxiv.org/abs/2401.14295) [2024] — Unified framework for multi-prompt reasoning topologies.
- [Towards Goal-oriented Prompt Engineering for Large Language Models: A Survey](https://arxiv.org/abs/2401.14043) [2024] — Focuses on prompts designed around explicit task goals.
- [Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning LLMs](https://arxiv.org/abs/2503.09567) [2025] — Distinguishes Long CoT from Short CoT in o1/R1-era models.
### Prompt Optimization and Automatic Prompting
- [OPRO: Large Language Models as Optimizers](https://arxiv.org/abs/2309.03409) [2023, NeurIPS 2024] — Uses LLMs as optimizers via meta-prompts; optimized prompts outperform human-designed ones by up to 50% on BBH.
- [DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines](https://arxiv.org/abs/2310.03714) [2023, ICLR 2024] — Framework for programming (not prompting) LLMs with automatic prompt optimization.
- [MIPRO: Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs](https://arxiv.org/abs/2406.11695) [2024, EMNLP 2024] — Bayesian optimization for multi-stage LM programs; up to 13% accuracy gains.
- [TextGrad: Automatic "Differentiation" via Text](https://arxiv.org/abs/2406.07496) [2024] — Treats compound AI systems as computation graphs with textual feedback as gradients. Published in Nature.
- [EvoPrompt](https://arxiv.org/abs/2309.08532) [2023, ACL 2024] — Evolutionary algorithm approach for automatically optimizing discrete prompts.
- [Meta Prompting for AI Systems](https://arxiv.org/abs/2311.11482) [2023, ICLR 2024 Workshop] — Example-agnostic structural templates formalized using category theory.
- [Prompt Engineering a Prompt Engineer (PE²)](https://arxiv.org/abs/2311.05661) [2024, ACL Findings] — Uses LLMs to meta-prompt themselves, refining prompts with step-by-step templates to significantly improve reasoning.
- [Large Language Models Are Human-Level Prompt Engineers](https://arxiv.org/abs/2211.01910) [2022] — Automatic prompt generation via APE.
- [Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning](https://arxiv.org/abs/2302.03668) [2023]
- [SPO: Self-Supervised Prompt Optimization](https://arxiv.org/abs/2502.06855) [2025] — Competitive performance at 1–6% of the cost of prior methods.
### Prompt Compression
- [LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression](https://arxiv.org/abs/2403.12968) [2024, ACL 2024] — 3x–6x faster than LLMLingua with GPT-4 data distillation.
- [LongLLMLingua](https://arxiv.org/abs/2310.06839) [2023, ACL 2024] — Question-aware compression for long contexts; 21.4% performance boost with 4x fewer tokens.
- [Prompt Compression for Large Language Models: A Survey](https://arxiv.org/abs/2410.12388) [2024] — Comprehensive survey of hard and soft prompt compression methods.
### Reasoning Advances
- [Scaling LLM Test-Time Compute Optimally](https://arxiv.org/abs/2408.03314) [2024] — Shows optimal test-time compute allocation can outperform 14x larger models.
- [DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning](https://arxiv.org/abs/2501.12948) [2025] — Pure RL-trained reasoning model matching o1; open-source with distilled variants.
- [s1: Simple Test-Time Scaling](https://arxiv.org/abs/2501.19393) [2025] — SFT on just 1,000 examples creates competitive reasoning model via "budget forcing."
- [Reasoning Language Models: A Blueprint](https://arxiv.org/abs/2501.11223) [2025] — Systematic framework organizing reasoning LM approaches.
- [Demystifying Long Chain-of-Thought Reasoning in LLMs](https://arxiv.org/abs/2502.03373) [2025] — Analyzes long CoT behavior in modern reasoning models.
- [Graph of Thoughts: Solving Elaborate Problems with LLMs](https://arxiv.org/abs/2308.09687) [2023, AAAI 2024] — Models thoughts as arbitrary graphs; 62% quality improvement over ToT on sorting.
- [Tree of Thoughts: Deliberate Problem Solving with LLMs](https://arxiv.org/abs/2305.10601) [2023, NeurIPS 2023] — Tree search over reasoning paths.
- [Everything of Thoughts](https://arxiv.org/abs/2311.04254) [2023] — Integrates CoT, ToT, and external solvers via MCTS.
- [Skeleton-of-Thought](https://arxiv.org/abs/2307.15337) [2023] — Parallel decoding via answer skeleton generation for up to 2.69x speedup.
- [Chain of Thought Prompting Elicits Reasoning in Large Language Models](https://arxiv.org/abs/2201.11903) [2022] — The foundational CoT paper.
- [Self-Consistency Improves Chain of Thought Reasoning](https://arxiv.org/abs/2203.11171) [2022] — Aggregating multiple CoT outputs for reliability.
- [Large Language Models are Zero-Shot Reasoners](https://arxiv.org/abs/2205.11916) [2022] — "Let's think step by step" as a zero-shot reasoning trigger.
- [ReAct: Synergizing Reasoning and Acting in Language Models](https://arxiv.org/abs/2210.03629) [2022] — Interleaving reasoning and tool use.
### In-Context Learning
- [Many-Shot In-Context Learning](https://arxiv.org/abs/2404.11018) [2024, NeurIPS 2024 Spotlight] — Significant gains scaling ICL to hundreds/thousands of examples; introduces Reinforced and Unsupervised ICL.
- [Many-Shot In-Context Learning in Multimodal Foundation Models](https://arxiv.org/abs/2405.09798) [2024] — Scales multimodal ICL to ~2,000 examples across 14 datasets.
- [Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?](https://arxiv.org/abs/2202.12837) [2022]
- [Fantastically Ordered Prompts and Where to Find Them](https://arxiv.org/abs/2104.08786) [2021] — Overcoming few-shot prompt order sensitivity.
- [Calibrate Before Use: Improving Few-Shot Performance of Language Models](https://arxiv.org/abs/2102.09690) [2021]
### Agentic Prompting and Multi-Agent Systems
- [Agentic Large Language Models: A Survey](https://arxiv.org/abs/2503.23037) [2025] — Comprehensive survey organizing agentic LLMs by reasoning, acting, and interacting capabilities.
- [Large Language Model based Multi-Agents: A Survey of Progress and Challenges](https://arxiv.org/abs/2402.01680) [2024] — Covers profiling, communication, and growth mechanisms.
- [Multi-Agent Collaboration Mechanisms: A Survey of LLMs](https://arxiv.org/abs/2501.06322) [2025] — Reviews debate and cooperation strategies in LLM-based multi-agent systems.
- [AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation](https://arxiv.org/abs/2308.08155) [2023] — Microsoft's foundational multi-agent framework paper.
- [ToolLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs](https://arxiv.org/abs/2307.16789) [2023, ICLR 2024] — Trains LLMs to use massive real-world API collections.
- [SWE-bench: Can Language Models Resolve Real-World GitHub Issues?](https://arxiv.org/abs/2310.06770) [2023, ICLR 2024] — The benchmark driving agentic coding progress.
- [AgentBench: Evaluating LLMs as Agents](https://arxiv.org/abs/2308.03688) [2023, ICLR 2024] — Benchmark across 8 environments.
- [PAL: Program-aided Language Models](https://arxiv.org/abs/2211.10435) [2023] — Offloading computation to code interpreters.
### Multimodal Prompting
- [Visual Prompting in Multimodal Large Language Models: A Survey](https://arxiv.org/abs/2409.15310) [2024] — First comprehensive survey on visual prompting methods in MLLMs.
- [Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V](https://arxiv.org/abs/2310.11441) [2023] — Visual markers dramatically improve visual grounding.
- [A Comprehensive Survey and Guide to Multimodal Large Language Models in Vision-Language Tasks](https://arxiv.org/abs/2411.06284) [2024] — Covers text, image, video, audio MLLMs.
- [Multimodal Chain-of-Thought Reasoning in Language Models](https://arxiv.org/abs/2302.00923) [2023]
- [From Prompt Engineering to Prompt Craft](https://arxiv.org/abs/2411.13422) [2024] — Design-research view of prompt "craft" for diffusion models.
### Structured Output and Format Control
- [Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of LLMs](https://arxiv.org/abs/2408.02442) [2024] — Examines how constraining outputs to structured formats impact
1. **Learn the basics** → [ChatGPT Prompt Engineering for Developers](https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/) (free, ~90 min)
2. **Read the guide** → [Prompt Engineering Guide by DAIR.AI](https://www.promptingguide.ai/) (open-source, comprehensive)
3. **Study provider docs** → [OpenAI Prompt Engineering Guide](https://platform.openai.com/docs/guides/prompt-engineering) · [Anthropic Prompt Engineering Guide](https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview)
4. **Understand where the field is heading** → [Anthropic: Effective Context Engineering for AI Agents](https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents)
5. **Read the research** → [The Prompt Report](https://arxiv.org/abs/2406.06608) — taxonomy of 58+ prompting techniques from 1,500+ papers
---
## Table of Contents
- [Papers](#papers)
- [Major Surveys](#major-surveys)
- [Prompt Optimization and Automatic Prompting](#prompt-optimization-and-automatic-prompting)
- [Prompt Compression](#prompt-compression)
- [Reasoning Advances](#reasoning-advances)
- [In-Context Learning](#in-context-learning)
- [Agentic Prompting and Multi-Agent Systems](#agentic-prompting-and-multi-agent-systems)
- [Multimodal Prompting](#multimodal-prompting)
- [Structured Output and Format Control](#structured-output-and-format-control)
- [Prompt Injection and Security](#prompt-injection-and-security)
- [Applications of Prompt Engineering](#applications-of-prompt-engineering)
- [Text-to-Image Generation](#text-to-image-generation)
- [Text-to-Music/Audio Generation](#text-to-musicaudio-generation)
- [Foundational Papers (Pre-2024)](#foundational-papers-pre-2024)
- [Tools and Code](#tools-and-code)
- [Prompt Management and Testing](#prompt-management-and-testing)
- [LLM Evaluation Tools](#llm-evaluation-tools)
- [Agent Frameworks](#agent-frameworks)
- [Prompt Optimization Tools](#prompt-optimization-tools)
- [Red Teaming and Prompt Security](#red-teaming-and-prompt-security)
- [MCP (Model Context Protocol)](#mcp-model-context-protocol)
- [Vibe Coding and AI Coding Assistants](#vibe-coding-and-ai-coding-assistants)
- [CLI-Based Coding Agents](#cli-based-coding-agents)
- [AI Code Editors / IDEs](#ai-code-editors--ides)
- [IDE Extensions / Plugins](#ide-extensions--plugins)
- [AI Coding Platforms / Cloud Agents](#ai-coding-platforms--cloud-agents)
- [Open-Source Coding Agent Frameworks](#open-source-coding-agent-frameworks)
- [Other Notable Repositories](#other-notable-repositories)
- [APIs](#apis)
- [Datasets and Benchmarks](#datasets-and-benchmarks)
- [Models](#models)
- [AI Content Detectors](#ai-content-detectors)
- [Books](#books)
- [Courses](#courses)
- [Tutorials and Guides](#tutorials-and-guides)
- [Videos](#videos)
- [Communities](#communities)
- [Autonomous Research & Self-Improving Agents](#autonomous-research--self-improving-agents)
- [How to Contribute](#how-to-contribute)
---
## Papers
📄
### Major Surveys
- [The Prompt Report: A Systematic Survey of Prompting Techniques](https://arxiv.org/abs/2406.06608) [2024] — Most comprehensive survey: taxonomy of 58 text and 40 multimodal prompting techniques from 1,500+ papers. Co-authored with OpenAI, Microsoft, Google, Stanford.
- [A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications](https://arxiv.org/abs/2402.07927) [2024] — 44 techniques across application areas with per-task performance summaries.
- [A Survey of Prompt Engineering Methods in LLMs for Different NLP Tasks](https://arxiv.org/abs/2407.12994) [2024] — 39 prompting methods across 29 NLP tasks.
- [A Survey of Automatic Prompt Engineering: An Optimization Perspective](https://arxiv.org/abs/2502.11560) [2025] — Formalizes auto-PE methods as discrete/continuous/hybrid optimization problems.
- [Efficient Prompting Methods for Large Language Models: A Survey](https://arxiv.org/abs/2404.01077) [2024] — Survey of efficiency-oriented prompting (compression, optimization, APE) for reducing compute and latency.
- [Navigate through Enigmatic Labyrinth: A Survey of Chain of Thought Reasoning](https://arxiv.org/abs/2309.15402) [2023, ACL 2024] — Systematic CoT survey.
- [Demystifying Chains, Trees, and Graphs of Thoughts](https://arxiv.org/abs/2401.14295) [2024] — Unified framework for multi-prompt reasoning topologies.
- [Towards Goal-oriented Prompt Engineering for Large Language Models: A Survey](https://arxiv.org/abs/2401.14043) [2024] — Focuses on prompts designed around explicit task goals.
- [Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning LLMs](https://arxiv.org/abs/2503.09567) [2025] — Distinguishes Long CoT from Short CoT in o1/R1-era models.
### Prompt Optimization and Automatic Prompting
- [OPRO: Large Language Models as Optimizers](https://arxiv.org/abs/2309.03409) [2023, NeurIPS 2024] — Uses LLMs as optimizers via meta-prompts; optimized prompts outperform human-designed ones by up to 50% on BBH.
- [DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines](https://arxiv.org/abs/2310.03714) [2023, ICLR 2024] — Framework for programming (not prompting) LLMs with automatic prompt optimization.
- [MIPRO: Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs](https://arxiv.org/abs/2406.11695) [2024, EMNLP 2024] — Bayesian optimization for multi-stage LM programs; up to 13% accuracy gains.
- [TextGrad: Automatic "Differentiation" via Text](https://arxiv.org/abs/2406.07496) [2024] — Treats compound AI systems as computation graphs with textual feedback as gradients. Published in Nature.
- [EvoPrompt](https://arxiv.org/abs/2309.08532) [2023, ACL 2024] — Evolutionary algorithm approach for automatically optimizing discrete prompts.
- [Meta Prompting for AI Systems](https://arxiv.org/abs/2311.11482) [2023, ICLR 2024 Workshop] — Example-agnostic structural templates formalized using category theory.
- [Prompt Engineering a Prompt Engineer (PE²)](https://arxiv.org/abs/2311.05661) [2024, ACL Findings] — Uses LLMs to meta-prompt themselves, refining prompts with step-by-step templates to significantly improve reasoning.
- [Large Language Models Are Human-Level Prompt Engineers](https://arxiv.org/abs/2211.01910) [2022] — Automatic prompt generation via APE.
- [Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning](https://arxiv.org/abs/2302.03668) [2023]
- [SPO: Self-Supervised Prompt Optimization](https://arxiv.org/abs/2502.06855) [2025] — Competitive performance at 1–6% of the cost of prior methods.
### Prompt Compression
- [LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression](https://arxiv.org/abs/2403.12968) [2024, ACL 2024] — 3x–6x faster than LLMLingua with GPT-4 data distillation.
- [LongLLMLingua](https://arxiv.org/abs/2310.06839) [2023, ACL 2024] — Question-aware compression for long contexts; 21.4% performance boost with 4x fewer tokens.
- [Prompt Compression for Large Language Models: A Survey](https://arxiv.org/abs/2410.12388) [2024] — Comprehensive survey of hard and soft prompt compression methods.
### Reasoning Advances
- [Scaling LLM Test-Time Compute Optimally](https://arxiv.org/abs/2408.03314) [2024] — Shows optimal test-time compute allocation can outperform 14x larger models.
- [DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning](https://arxiv.org/abs/2501.12948) [2025] — Pure RL-trained reasoning model matching o1; open-source with distilled variants.
- [s1: Simple Test-Time Scaling](https://arxiv.org/abs/2501.19393) [2025] — SFT on just 1,000 examples creates competitive reasoning model via "budget forcing."
- [Reasoning Language Models: A Blueprint](https://arxiv.org/abs/2501.11223) [2025] — Systematic framework organizing reasoning LM approaches.
- [Demystifying Long Chain-of-Thought Reasoning in LLMs](https://arxiv.org/abs/2502.03373) [2025] — Analyzes long CoT behavior in modern reasoning models.
- [Graph of Thoughts: Solving Elaborate Problems with LLMs](https://arxiv.org/abs/2308.09687) [2023, AAAI 2024] — Models thoughts as arbitrary graphs; 62% quality improvement over ToT on sorting.
- [Tree of Thoughts: Deliberate Problem Solving with LLMs](https://arxiv.org/abs/2305.10601) [2023, NeurIPS 2023] — Tree search over reasoning paths.
- [Everything of Thoughts](https://arxiv.org/abs/2311.04254) [2023] — Integrates CoT, ToT, and external solvers via MCTS.
- [Skeleton-of-Thought](https://arxiv.org/abs/2307.15337) [2023] — Parallel decoding via answer skeleton generation for up to 2.69x speedup.
- [Chain of Thought Prompting Elicits Reasoning in Large Language Models](https://arxiv.org/abs/2201.11903) [2022] — The foundational CoT paper.
- [Self-Consistency Improves Chain of Thought Reasoning](https://arxiv.org/abs/2203.11171) [2022] — Aggregating multiple CoT outputs for reliability.
- [Large Language Models are Zero-Shot Reasoners](https://arxiv.org/abs/2205.11916) [2022] — "Let's think step by step" as a zero-shot reasoning trigger.
- [ReAct: Synergizing Reasoning and Acting in Language Models](https://arxiv.org/abs/2210.03629) [2022] — Interleaving reasoning and tool use.
### In-Context Learning
- [Many-Shot In-Context Learning](https://arxiv.org/abs/2404.11018) [2024, NeurIPS 2024 Spotlight] — Significant gains scaling ICL to hundreds/thousands of examples; introduces Reinforced and Unsupervised ICL.
- [Many-Shot In-Context Learning in Multimodal Foundation Models](https://arxiv.org/abs/2405.09798) [2024] — Scales multimodal ICL to ~2,000 examples across 14 datasets.
- [Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?](https://arxiv.org/abs/2202.12837) [2022]
- [Fantastically Ordered Prompts and Where to Find Them](https://arxiv.org/abs/2104.08786) [2021] — Overcoming few-shot prompt order sensitivity.
- [Calibrate Before Use: Improving Few-Shot Performance of Language Models](https://arxiv.org/abs/2102.09690) [2021]
### Agentic Prompting and Multi-Agent Systems
- [Agentic Large Language Models: A Survey](https://arxiv.org/abs/2503.23037) [2025] — Comprehensive survey organizing agentic LLMs by reasoning, acting, and interacting capabilities.
- [Large Language Model based Multi-Agents: A Survey of Progress and Challenges](https://arxiv.org/abs/2402.01680) [2024] — Covers profiling, communication, and growth mechanisms.
- [Multi-Agent Collaboration Mechanisms: A Survey of LLMs](https://arxiv.org/abs/2501.06322) [2025] — Reviews debate and cooperation strategies in LLM-based multi-agent systems.
- [AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation](https://arxiv.org/abs/2308.08155) [2023] — Microsoft's foundational multi-agent framework paper.
- [ToolLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs](https://arxiv.org/abs/2307.16789) [2023, ICLR 2024] — Trains LLMs to use massive real-world API collections.
- [SWE-bench: Can Language Models Resolve Real-World GitHub Issues?](https://arxiv.org/abs/2310.06770) [2023, ICLR 2024] — The benchmark driving agentic coding progress.
- [AgentBench: Evaluating LLMs as Agents](https://arxiv.org/abs/2308.03688) [2023, ICLR 2024] — Benchmark across 8 environments.
- [PAL: Program-aided Language Models](https://arxiv.org/abs/2211.10435) [2023] — Offloading computation to code interpreters.
### Multimodal Prompting
- [Visual Prompting in Multimodal Large Language Models: A Survey](https://arxiv.org/abs/2409.15310) [2024] — First comprehensive survey on visual prompting methods in MLLMs.
- [Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V](https://arxiv.org/abs/2310.11441) [2023] — Visual markers dramatically improve visual grounding.
- [A Comprehensive Survey and Guide to Multimodal Large Language Models in Vision-Language Tasks](https://arxiv.org/abs/2411.06284) [2024] — Covers text, image, video, audio MLLMs.
- [Multimodal Chain-of-Thought Reasoning in Language Models](https://arxiv.org/abs/2302.00923) [2023]
- [From Prompt Engineering to Prompt Craft](https://arxiv.org/abs/2411.13422) [2024] — Design-research view of prompt "craft" for diffusion models.
### Structured Output and Format Control
- [Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of LLMs](https://arxiv.org/abs/2408.02442) [2024] — Examines how constraining outputs to structured formats impact
Extension points exported contracts — how you extend this code
SectionCardData (Interface)(no doc)
website/src/components/SectionGrid.tsx
Resource (Interface)
(no doc)
website/src/lib/types.ts
Paper (Interface)
(no doc)
website/src/lib/types.ts
APIModel (Interface)
(no doc)
website/src/lib/types.ts
APIProvider (Interface)
(no doc)
website/src/lib/types.ts
Core symbols most depended-on inside this repo
stripMarkdowncalled by 32
website/src/lib/parser.ts
findSection
called by 12
website/src/lib/parser.ts
fetchSiteData
called by 7
website/src/lib/github.ts
buildSearchIndex
called by 7
website/src/lib/parser.ts
extractLink
called by 6
website/src/lib/parser.ts
parseTableRows
called by 5
website/src/lib/parser.ts
parseListItems
called by 4
website/src/lib/parser.ts
extractAllLinks
called by 3
website/src/lib/parser.ts
Shape
Languages
TypeScript92%
Python8%
Modules by API surface
website/src/lib/parser.ts18 symbols
website/src/lib/types.ts9 symbols
scripts/sync-autoresearch.py5 symbols
website/src/lib/github.ts3 symbols
website/src/hooks/useSearch.ts2 symbols
website/src/components/ThemeToggle.tsx2 symbols
website/src/components/SectionGrid.tsx2 symbols
website/src/components/SearchDialog.tsx2 symbols
website/src/components/ResourceCard.tsx2 symbols
website/src/components/EmailCapture.tsx2 symbols
website/src/app/models/ModelsClient.tsx2 symbols
website/src/app/learn/LearnClient.tsx2 symbols
Dependencies from manifests, versioned
@eslint/eslintrc3 · 1×
@tailwindcss/postcss4 · 1×
@types/node20 · 1×
@types/react19 · 1×
@types/react-dom19 · 1×
eslint9 · 1×
eslint-config-next15.5.12 · 1×
fuse.js7.1.0 · 1×
next15.5.12 · 1×
react19.1.0 · 1×
react-dom19.1.0 · 1×
resend6.9.2 · 1×
For agents
$ claude mcp add Awesome-Prompt-Engineering \
-- python -m otcore.mcp_server <graph>