github.com/PaddlePaddle/PaddleX @v3.7.2
README
![]()
<a href="https://github.com/PaddlePaddle/PaddleX/raw/v3.7.2/LICENSE"><img src="https://img.shields.io/badge/License-Apache%202-red.svg"></a>
<a href=""><img src="https://img.shields.io/badge/Python-3.8~3.13-blue.svg"></a>
<a href=""><img src="https://img.shields.io/badge/OS-Linux%2C%20Windows%2C%20Mac-orange.svg"></a>
<a href=""><img src="https://img.shields.io/badge/hardware-CPU%2C%20GPU%2C%20XPU%2C%20NPU%2C%20MLU%2C%20DCU-yellow.svg"></a>
🌟 Features | >🌐 Online Experience|🚀 Quick Start | 📖 Documentation | 🔥Capabilities | 📋 Models
🇨🇳 Simplified Chinese | 🇬🇧 English
🔍 Introduction
PaddleX 3.0 is a low-code development tool for AI models built on the PaddlePaddle framework. It integrates numerous ready-to-use pre-trained models, enabling full-process development from model training to inference, supporting a variety of mainstream hardware both domestic and international, and aiding AI developers in industrial practice.
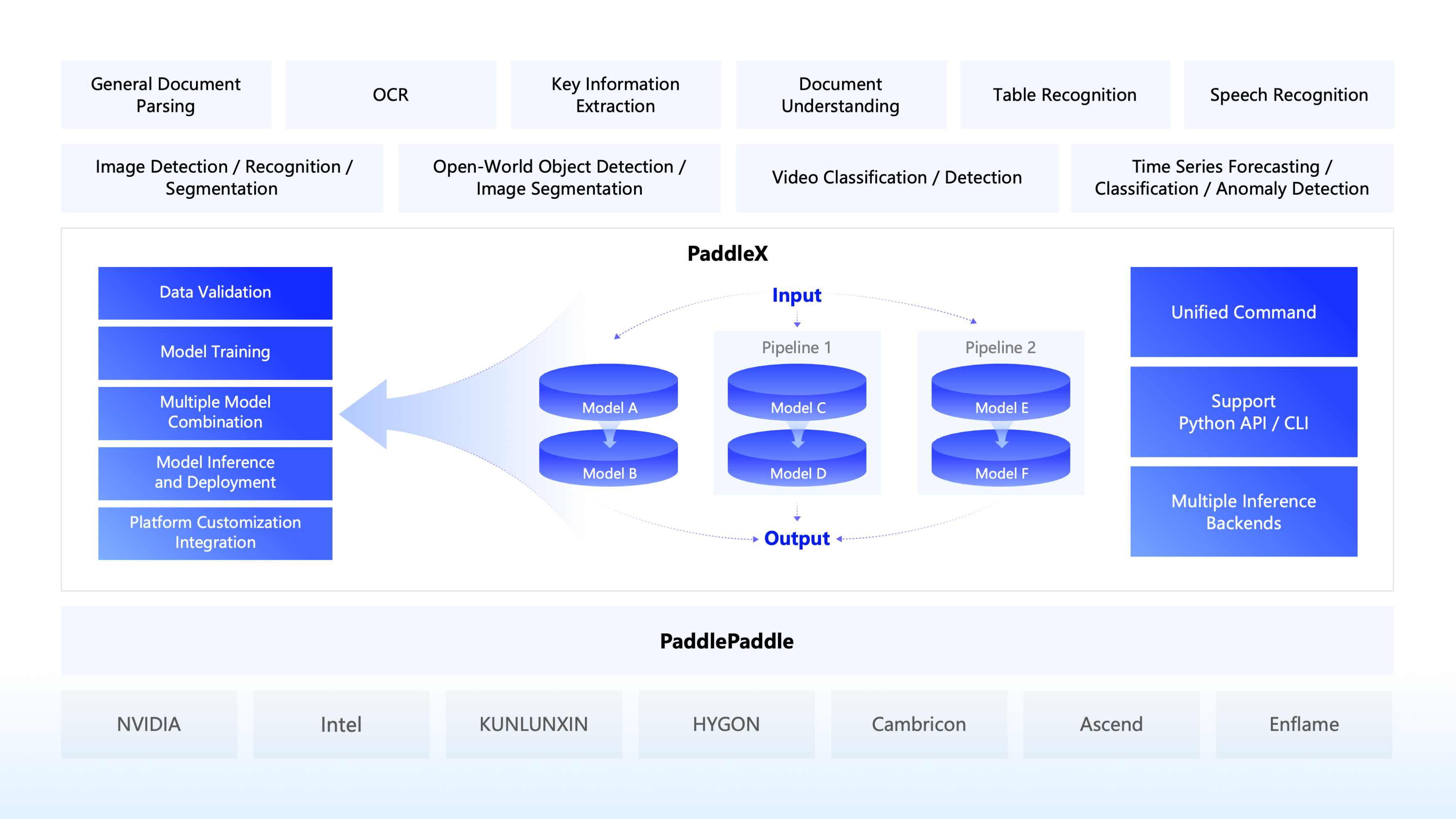
🌟 Why PaddleX ?
🎨 Rich Models One-click Call: Integrate over 200 PaddlePaddle models covering multiple key areas such as OCR, object detection, and time series forecasting into 33 pipelines. Experience the model effects quickly through easy Python API calls. Also supports 39 modules for easy model combination use by developers.
🚀 High Efficiency and Low barrier of entry: Achieve model full-process development based on graphical interfaces and unified commands, creating 8 featured model pipelines that combine large and small models, semi-supervised learning of large models, and multi-model fusion, greatly reducing the cost of iterating models.
🌐 Flexible Deployment in Various Scenarios: Support various deployment methods such as high-performance inference, serving, and lite deployment to ensure efficient operation and rapid response of models in different application scenarios.
🔧 Efficient Support for Mainstream Hardware: Support seamless switching of various mainstream hardware such as NVIDIA GPUs, Kunlun XPU, Ascend NPU, and Cambricon MLU to ensure efficient operation.
📣 Recent Updates
🔥🔥 2025.10.16, PaddleX v3.3.0 Released
- Added support for inference and deployment of PaddleOCR-VL and PP-OCRv5 multilingual models.
🔥🔥 2025.8.20, PaddleX v3.2.0 Released
-
Deployment Capability Upgrades:
- Fully supports PaddlePaddle framework versions 3.1.0 and 3.1.1.
- High-performance inference supports CUDA 12, with backend options including Paddle Inference and ONNX Runtime.
- High-stability serving solution is fully open-sourced, enabling users to customize Docker images and SDKs as needed.
- High-stability serving solution supports invocation via manually constructed HTTP requests, allowing client applications to be developed in any programming language.
-
Key Model Additions:
- Added training, inference, and deployment support for PP-OCRv5 English, Thai, and Greek recognition models. The PP-OCRv5 English model delivers an 11% improvement over the main PP-OCRv5 model in English scenarios, with the Thai model achieving an accuracy of 82.68% and the Greek model 89.28%.
-
Benchmark Enhancements:
- All pipelines support fine-grained benchmarking, enabling the measurement of end-to-end inference time as well as per-layer and per-module latency data to assist with performance analysis.
- Added key metrics such as inference latency and memory usage for commonly used configurations on mainstream hardware to the documentation, providing deployment reference for users.
-
Bug Fixes:
- Fixed an issue where invalid input image file formats could cause recursive calls.
- Resolved ineffective parameter settings for chart recognition, seal recognition, and document pre-processing in the configuration files for the PP-DocTranslation and PP-StructureV3 pipelines.
- Fixed an issue where PDF files were not properly closed after inference.
-
Other Updates:
- Added support for Windows users with NVIDIA 50-series graphics cards; users can install the corresponding PaddlePaddle framework version as per the installation guide.
- The PP-OCR model series now supports returning coordinates for individual characters.
- The
model_nameparameter inPaddlePredictorOptionhas been moved toPaddleInfer, improving usability. - Refactored the official model download logic, with new support for multiple model hosting platforms such as AIStudio and ModelScope.
🔥🔥 2025.6.28, PaddleX v3.1.0 Released
- Key Models:
- Added PP-OCRv5 Multilingual Text Recognition Model, supporting training and inference workflows for text recognition in 37 languages, including French, Spanish, Portuguese, Russian, Korean, and more. Average precision increased by over 30%.
- Upgraded PP-Chart2Table model in PP-StructureV3. Chart-to-table conversion capability further improved, with RMS-F1 on our internal evaluation set increased by 9.36 percentage points (71.24% -> 80.60%).
- Key Pipelines:
- Added document translation pipeline PP-DocTranslation based on PP-StructureV3 and ERNIE 4.5 Turbo. Supports translation of Markdown documents, various complex-layout PDF documents, and document images, with results saved as Markdown format documents.
🔥🔥 2025.5.20: PaddleX v3.0.0 Released
Core upgrades are as follows:
- Rich Model Library:
- Extensive Model Coverage: PaddleX 3.0 includes 270+ models, covering diverse scenarios such as image/video classification/detection/segmentation, OCR, speech recognition, time series analysis, and more.
-
Mature Solutions: Built on this robust model library, PaddleX 3.0 offers critical and production-ready AI solutions, including general document parsing, key information extraction, document understanding, table recognition, and general image recognition.
-
Unified Inference API & Enhanced Deployment Capabilities:
- Standardized Inference Interface: Reduces API fragmentation across model types, lowering the learning curve for users and accelerating enterprise adoption.
- Multi-Model Composition: Complex tasks can be efficiently tackled by combining different models, achieving synergistic performance (1+1>2).
-
Upgraded Deployment: Unified commands now manage deployments for diverse models, supporting multi-GPU inference and multi-instance serving deployments.
-
Full Compatibility with PaddlePaddle Framework 3.0:
- Leveraging New Paddle 3.0 Features:
- Compiler-accelerated training: Enable by appending
-o Global.dy2st=Trueto training commands. Most GPU-based models see >10% speed gains, with some exceeding 30%. - Inference upgrades: Full adaptation to Paddle 3.0’s Program Intermediate Representation (PIR) enhances flexibility and compatibility. Static graph models now use
xxx.jsoninstead ofxxx.pdmodel.
- Compiler-accelerated training: Enable by appending
-
ONNX Model Support: Seamless format conversion via the Paddle2ONNX plugin.
-
Flagship Capabilities:
- PP-OCRv5: Powers multi-hardware inference, multi-backend support, and serving deployments for this industry-leading OCR system.
- PP-StructureV3: Orchestrates 15+ models in hybrid (serial/parallel) pipelines, achieving SOTA accuracy on OmniDocBench.
-
PP-ChatOCRv4: Integrates with PP-DocBee2 and ERNIE 4.5Turbo, boosting key information extraction accuracy by 15.7 percentage points over the previous generation.
-
Multi-Hardware Support:
- Broad Compatibility: Training and inference supported on NVIDIA, Intel, Apple M-series, Kunlunxin, Ascend, Cambricon, Hygon, Enflame, and more.
- Ascend-Optimized: 200+ fully adapted models, including 21 OM-accelerated inference models, plus key solutions like PP-OCRv5 and PP-StructureV3.
- Kunlunxin-Optimized: Critical classification, detection, and OCR models (including PP-OCRv5) are fully supported.
🔠 Explanation of Pipeline
PaddleX is dedicated to achieving pipeline-level model training, inference, and deployment. A pipeline refers to a series of predefined development processes for specific AI tasks, which includes a combination of single models (single-function modules) capable of independently completing a certain type of task.
📊 What can PaddleX do?
All pipelines of PaddleX support online experience on AI Studio and local fast inference. You can quickly experience the effects of each pre-trained pipeline. If you are satisfied with the effects of the pre-trained pipeline, you can directly perform high-performance inference / serving / edge deployment on the pipeline. If not satisfied, you can also Custom Development to improve the pipeline effect. For the complete pipeline development process, please refer to the PaddleX pipeline Development Tool Local Use Tutorial.
In addition, PaddleX provides developers with a full-process efficient model training and deployment tool based on a cloud-based GUI. Developers do not need code development, just need to prepare a dataset that meets the pipeline requirements to quickly start model training. For details, please refer to the tutorial "Developing Industrial-level AI Models with Zero Barrier".
| Pipeline | Online Experience | Local Inference | High-Performance Inference | Serving | On-Device Deployment | Custom Development | Zero-Code Development On AI Studio |
|---|---|---|---|---|---|---|---|
| OCR | Link | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| PP-ChatOCRv3 | Link | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| PP-ChatOCRv4 | Link | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| Table Recognition | Link | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| Object Detection | Link | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Instance Segmentation | Link | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| Image Classification | Link | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Semantic Segmentation |
Core symbols most depended-on inside this repo
getShape
Languages
Modules by API surface
Used by 1 indexed graphs manifest dependencies, hub-wide
Dependencies from manifests, versioned
For agents
$ claude mcp add PaddleX \
-- python -m otcore.mcp_server <graph>