hub / github.com/PaddlePaddle/PaddleNLP
github.com/PaddlePaddle/PaddleNLP @v2.8.1 sqlite
25,805 symbols
102,594 edges
2,612 files
7,312 documented · 28%
README
简体中文🀄 | English🌎

<a href="https://github.com/PaddlePaddle/PaddleNLP/raw/v2.8.1/LICENSE"><img src="https://img.shields.io/badge/license-Apache%202-dfd.svg"></a>
<a href="https://github.com/PaddlePaddle/PaddleNLP/releases"><img src="https://img.shields.io/github/v/release/PaddlePaddle/PaddleNLP?color=ffa"></a>
<a href=""><img src="https://img.shields.io/badge/python-3.7+-aff.svg"></a>
<a href=""><img src="https://img.shields.io/badge/os-linux%2C%20win%2C%20mac-pink.svg"></a>
<a href="https://github.com/PaddlePaddle/PaddleNLP/graphs/contributors"><img src="https://img.shields.io/github/contributors/PaddlePaddle/PaddleNLP?color=9ea"></a>
<a href="https://github.com/PaddlePaddle/PaddleNLP/commits"><img src="https://img.shields.io/github/commit-activity/m/PaddlePaddle/PaddleNLP?color=3af"></a>
<a href="https://pypi.org/project/paddlenlp/"><img src="https://img.shields.io/pypi/dm/paddlenlp?color=9cf"></a>
<a href="https://github.com/PaddlePaddle/PaddleNLP/issues"><img src="https://img.shields.io/github/issues/PaddlePaddle/PaddleNLP?color=9cc"></a>
<a href="https://github.com/PaddlePaddle/PaddleNLP/stargazers"><img src="https://img.shields.io/github/stars/PaddlePaddle/PaddleNLP?color=ccf"></a>
Features | Installation | Quick Start | API Reference | Community
**PaddleNLP** is a NLP library that is both **easy to use** and **powerful**. It aggregates high-quality pretrained models in the industry and provides a **plug-and-play** development experience, covering a model library for various NLP scenarios. With practical examples from industry practices, PaddleNLP can meet the needs of developers who require **flexible customization**.
## News 📢
* **2024.01.04 [PaddleNLP v2.7](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.7.0)**: The LLM experience is fully upgraded, and the tool chain LLM entrance is unified. Unify the implementation code of pre-training, fine-tuning, compression, inference and deployment to the `PaddleNLP/llm` directory. The new [LLM Toolchain Documentation](https://paddlenlp.readthedocs.io/zh/latest/llm/finetune.html) provides one-stop guidance for users from getting started with LLM to business deployment and launch. The full breakpoint storage mechanism Unified Checkpoint greatly improves the versatility of LLM storage. Efficient fine-tuning upgrade supports the simultaneous use of efficient fine-tuning + LoRA, and supports QLoRA and other algorithms.
* **2023.08.15 [PaddleNLP v2.6](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.6.0)**: Release [Full-process LLM toolchain](./llm) , covering all aspects of pre-training, fine-tuning, compression, inference and deployment, providing users with end-to-end LLM solutions and one-stop development experience; built-in [4D parallel distributed Trainer](./docs/trainer.md ), [Efficient fine-tuning algorithm LoRA/Prefix Tuning](./llm#33-lora), [Self-developed INT8/INT4 quantization algorithm](./llm#6-quantization), etc.; fully supports [LLaMA 1/2](./llm/llama), [BLOOM](.llm/bloom), [ChatGLM 1/2](./llm/chatglm), [GLM](./llm/glm), [OPT](./llm/opt) and other mainstream LLMs.
## Installation
### Prerequisites
* python >= 3.7
* paddlepaddle >= 2.6.0
More information about PaddlePaddle installation please refer to [PaddlePaddle's Website](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/conda/linux-conda.html).
### Python pip Installation
pip install --upgrade paddlenlp
or you can install the latest develop branch code with the following command:
pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.html
## Features
#### 📦 Out-of-Box NLP Toolset
#### 🤗 Awesome Chinese Model Zoo
#### 🎛️ Industrial End-to-end System
#### 🚀 High Performance Distributed Training and Inference
### Out-of-Box NLP Toolset
Taskflow aims to provide off-the-shelf NLP pre-built task covering NLU and NLG technique, in the meanwhile with extremely fast inference satisfying industrial scenario.
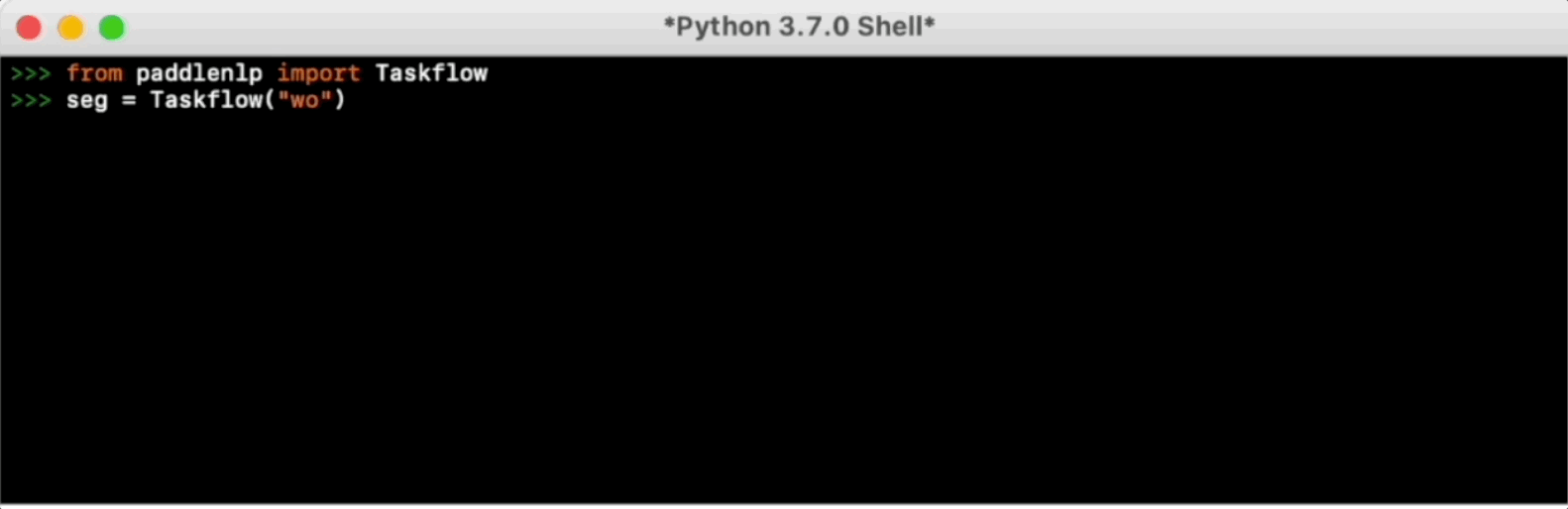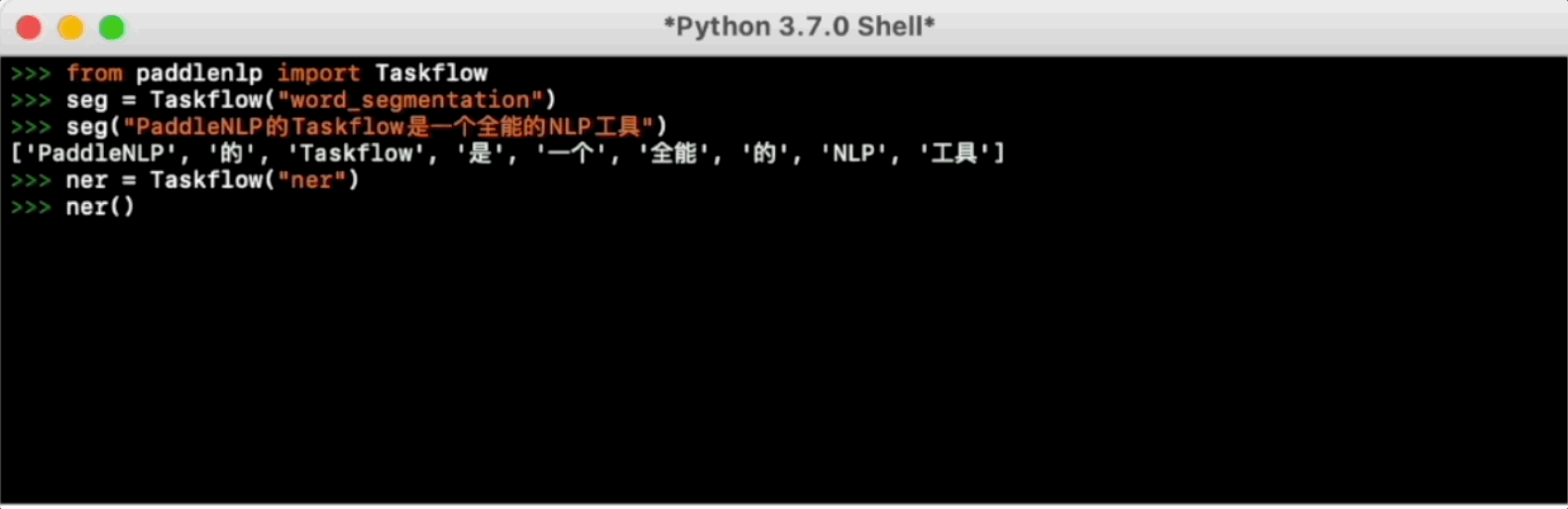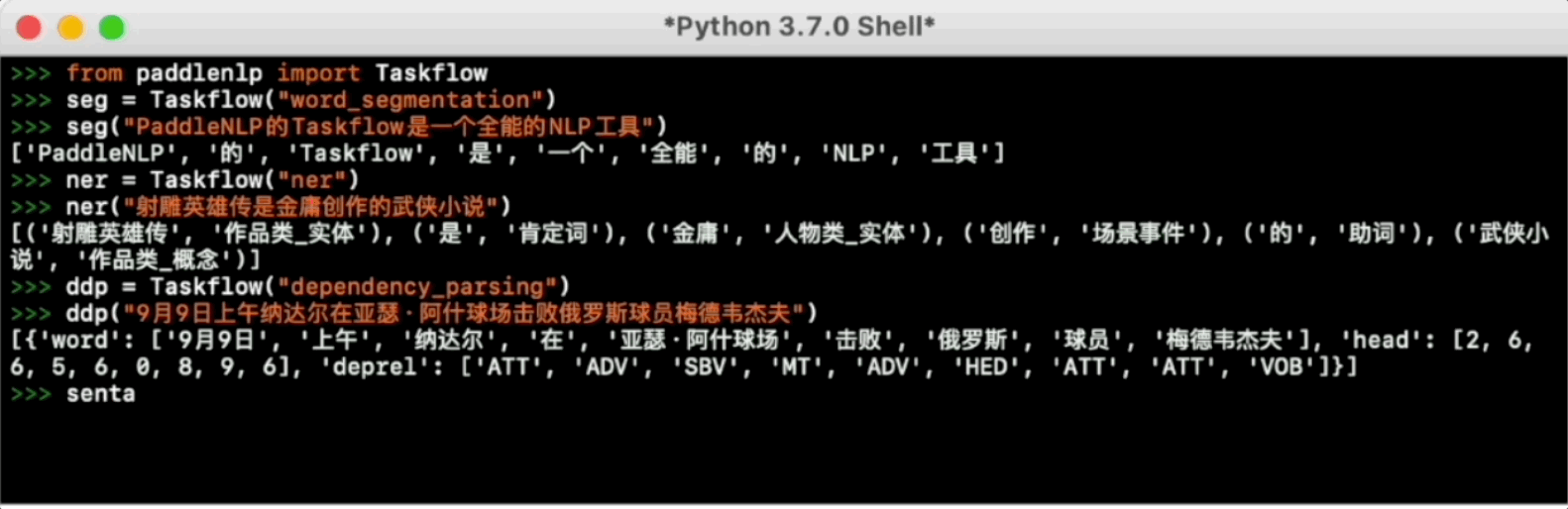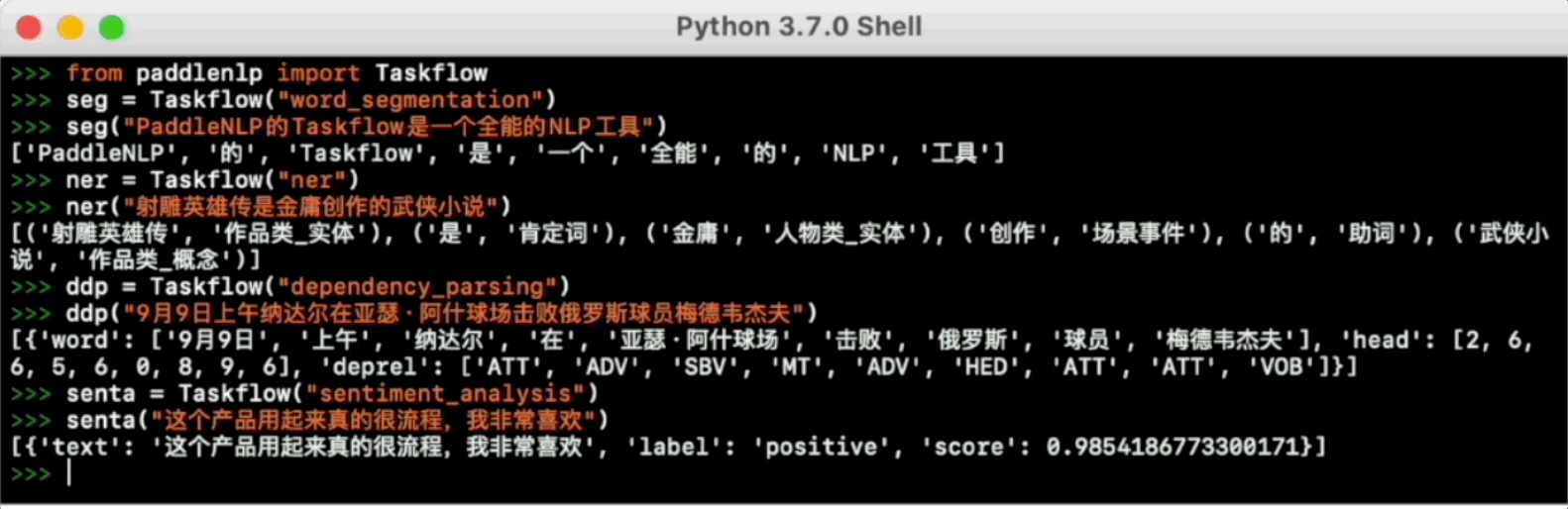
For more usage please refer to [Taskflow Docs](./docs/model_zoo/taskflow.md).
### Awesome Chinese Model Zoo
#### 🀄 Comprehensive Chinese Transformer Models
We provide **45+** network architectures and over **500+** pretrained models. Not only includes all the SOTA model like ERNIE, PLATO and SKEP released by Baidu, but also integrates most of the high-quality Chinese pretrained model developed by other organizations. Use `AutoModel` API to **⚡SUPER FAST⚡** download pretrained models of different architecture. We welcome all developers to contribute your Transformer models to PaddleNLP!
from paddlenlp.transformers import *
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
bert = AutoModel.from_pretrained('bert-wwm-chinese')
albert = AutoModel.from_pretrained('albert-chinese-tiny')
roberta = AutoModel.from_pretrained('roberta-wwm-ext')
electra = AutoModel.from_pretrained('chinese-electra-small')
gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')
Due to the computation limitation, you can use the ERNIE-Tiny light models to accelerate the deployment of pretrained models.
# 6L768H
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
# 6L384H
ernie = AutoModel.from_pretrained('ernie-3.0-mini-zh')
# 4L384H
ernie = AutoModel.from_pretrained('ernie-3.0-micro-zh')
# 4L312H
ernie = AutoModel.from_pretrained('ernie-3.0-nano-zh')
Unified API experience for NLP task like semantic representation, text classification, sentence matching, sequence labeling, question answering, etc.
import paddle
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
text = tokenizer('natural language processing')
# Semantic Representation
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
# Text Classificaiton and Matching
model = AutoModelForSequenceClassification.from_pretrained('ernie-3.0-medium-zh')
# Sequence Labeling
model = AutoModelForTokenClassification.from_pretrained('ernie-3.0-medium-zh')
# Question Answering
model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')
#### Wide-range NLP Task Support
PaddleNLP provides rich examples covering mainstream NLP task to help developers accelerate problem solving. You can find our powerful transformer [Model Zoo](./model_zoo), and wide-range NLP application [examples](./examples) with detailed instructions.
Also you can run our interactive [Notebook tutorial](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995) on AI Studio, a powerful platform with **FREE** computing resource.
PaddleNLP Transformer model summary (click to show details)
| Model | Sequence Classification | Token Classification | Question Answering | Text Generation | Multiple Choice |
| :----------------- | ----------------------- | -------------------- | ------------------ | --------------- | --------------- |
| ALBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
| BERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BlenderBot | ❌ | ❌ | ❌ | ✅ | ❌ |
| ChineseBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| CTRL | ✅ | ❌ | ❌ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE-CTM | ❌ | ✅ | ❌ | ❌ | ❌ |
| ERNIE-Doc | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-GEN | ❌ | ❌ | ❌ | ✅ | ❌ |
| ERNIE-Gram | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-M | ✅ | ✅ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| Funnel-Transformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| GPT | ✅ | ✅ | ❌ | ✅ | ❌ |
| LayoutLM | ✅ | ✅ | ❌ | ❌ | ❌ |
| LayoutLMv2 | ❌ | ✅ | ❌ | ❌ | ❌ |
| LayoutXLM | ❌ | ✅ | ❌ | ❌ | ❌ |
| LUKE | ❌ | ✅ | ✅ | ❌ | ❌ |
| mBART | ✅ | ❌ | ✅ | ❌ | ✅ |
| MegatronBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| MobileBERT | ✅ | ❌ | ✅ | ❌ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| NEZHA | ✅ | ✅ | ✅ | ❌ | ✅ |
| PP-MiniLM | ✅ | ❌ | ❌ | ❌ | ❌ |
| ProphetNet | ❌ | ❌ | ❌ | ✅ | ❌ |
| Reformer | ✅ | ❌ | ✅ | ❌ | ❌ |
| RemBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ❌ | ❌ |
| SKEP | ✅ | ✅ | ❌ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| T5 | ❌ | ❌ | ❌ | ✅ | ❌ |
| TinyBERT | ✅ | ❌ | ❌ | ❌ | ❌ |
| UnifiedTransformer | ❌ | ❌ | ❌ | ✅ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ❌ | ✅ |
For more pretrained model usage, please refer to [Transformer API Docs](./docs/model_zoo/index.rst).
### Industrial End-to-end System
We provide high value scenarios including information extraction, semantic retrieval, question answering high-value.
For more details industrial cases please refer to [Applications](./applications).
#### 🔍 Neural Search System
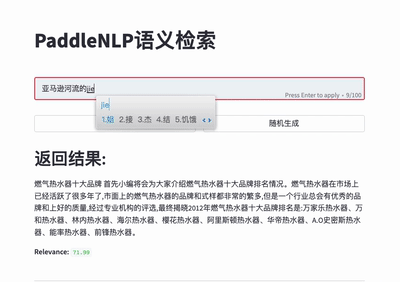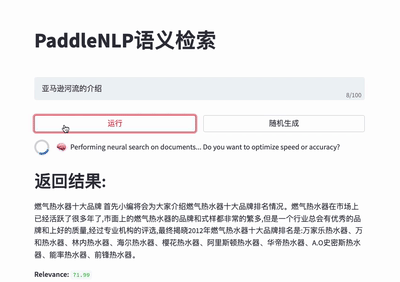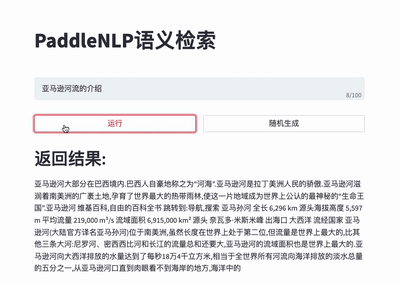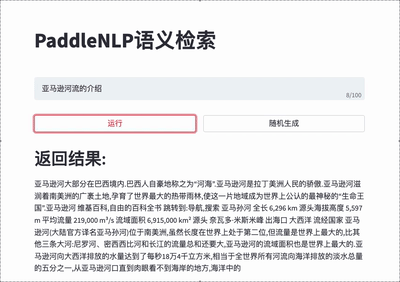 For more details please refer to [Neural Search](./applications/neural_search).
#### ❓ Question Answering System
We provide question answering pipeline which can support FAQ system, Document-level Visual Question answering system based on [🚀RocketQA](https://github.com/PaddlePaddle/RocketQA).
For more details please refer to [Neural Search](./applications/neural_search).
#### ❓ Question Answering System
We provide question answering pipeline which can support FAQ system, Document-level Visual Question answering system based on [🚀RocketQA](https://github.com/PaddlePaddle/RocketQA).
 For more details
For more details
pip install --upgrade paddlenlp
pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.html
from paddlenlp.transformers import *
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
bert = AutoModel.from_pretrained('bert-wwm-chinese')
albert = AutoModel.from_pretrained('albert-chinese-tiny')
roberta = AutoModel.from_pretrained('roberta-wwm-ext')
electra = AutoModel.from_pretrained('chinese-electra-small')
gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')
# 6L768H
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
# 6L384H
ernie = AutoModel.from_pretrained('ernie-3.0-mini-zh')
# 4L384H
ernie = AutoModel.from_pretrained('ernie-3.0-micro-zh')
# 4L312H
ernie = AutoModel.from_pretrained('ernie-3.0-nano-zh')
import paddle
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
text = tokenizer('natural language processing')
# Semantic Representation
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
# Text Classificaiton and Matching
model = AutoModelForSequenceClassification.from_pretrained('ernie-3.0-medium-zh')
# Sequence Labeling
model = AutoModelForTokenClassification.from_pretrained('ernie-3.0-medium-zh')
# Question Answering
model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')
Core symbols most depended-on inside this repo
joincalled by 3826
paddlenlp/prompt/prompt_tokenizer.py
append
called by 2047
pipelines/pipelines/schema.py
append
called by 1649
examples/machine_translation/transformer/reader.py
from_pretrained
called by 1369
paddlenlp/peft/lora/lora_model.py
append
called by 1310
paddlenlp/generation/logits_process.py
to_tensor
called by 1059
examples/information_extraction/DuUIE/inference.py
eval
called by 1040
paddlenlp/peft/lora/lora_model.py
split
called by 968
paddlenlp/transformers/tokenizer_utils.py
Shape
Languages
Python100%
Java1%
Modules by API surface
paddlenlp/transformers/speecht5/modeling.py181 symbols
tests/trainer/test_unified_checkpoint.py147 symbols
paddlenlp/taskflow/utils.py129 symbols
tests/transformers/speecht5/test_modeling.py126 symbols
paddlenlp/transformers/clap/modeling.py121 symbols
paddlenlp/transformers/reformer/modeling.py108 symbols
paddlenlp/transformers/tokenizer_utils_base.py104 symbols
paddlenlp/transformers/funnel/modeling.py97 symbols
paddlenlp/transformers/deberta_v2/modeling.py94 symbols
paddlenlp/transformers/deberta/modeling.py93 symbols
fast_tokenizer/python/fast_tokenizer/c_wrap.py91 symbols
paddlenlp/data/indexed_dataset.py87 symbols
Used by 1 indexed graphs manifest dependencies, hub-wide
Dependencies from manifests, versioned
Pillow9.3.0 · 1×
PyMuPDF1.20.2 · 1×
PyYAML5.4.1 · 1×
aiohttp3.8.4 · 1×
aiosignal1.3.1 · 1×
aistudio-sdk0.1.3 · 1×
async-timeout4.0.2 · 1×
attrdict2.0.1 · 1×
attrs23.1.0 · 1×
bce-python-sdk0.8.74 · 1×
bitsandbytes0.39.0 · 1×
blobfile1.3.3 · 1×
For agents
$ claude mcp add PaddleNLP \
-- python -m otcore.mcp_server <graph>