github.com/NVIDIA-NeMo/RL @v0.6.0 sqlite
README
# NeMo RL: A Scalable and Efficient Post-Training Library
![]()

Documentation | Discussions | Contributing
📣 News
- [04/06/2026] New Model Support
- Added support for Qwen3.5 dense and MoE models (LLM and VLM) for GRPO training.
- Added support for GLM-4.7-Flash for GRPO training.
- Recipes: grpo-qwen3.5-9b-1n8g-megatron.yaml, grpo-qwen3.5-35ba3b-2n8g-megatron-ep16.yaml, grpo-glm47-flash-4n8g-automodel.yaml
- [03/12/2026] GDPO Support
- Enabling Group reward-Decoupled Normalization Policy Optimization (GDPO) for multi-reward RL training is now supported.
- Example: gdpo_math_1B.yaml
- Support Async RL training
- WIP: Nemo-gym compatibility
- [03/11/2026] Nemotron-3-Super was post-trained with NeMo-RL! Follow this guide to reproduce the full RL training recipe.
- [02/04/2026] LoRA Support
- LoRA SFT is supported on both DTensor and Megatron Core backends.
- LoRA GRPO is supported on both DTensor and Megatron Core backends.
- LoRA DPO is supported on both DTensor and Megatron Core backends.
- Nano v3 LoRA recipes:
- [01/30/2026] Release v0.5.0!
- Both linux/amd64 and linux/arm64 Docker containers are available on NGC nvcr.io/nvidia/nemo-rl:v0.5.0.
- NeMo-Gym + NeMo-RL support
- 📊 View the release run metrics on Google Colab to get a head start on your experimentation.
Previous News
- [12/15/2025] NeMo-RL is the framework that trained NVIDIA-NeMotron-3-Nano-30B-A3B-FP8! This guide provides reproducible instructions for the post-training process.
- [10/10/2025] DAPO Algorithm Support
NeMo RL now supports Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) algorithm that extends GRPO with Clip-Higher, Dynamic Sampling, Token-Level Policy Gradient Loss, and Overlong Reward Shaping for more stable and efficient RL training. See the DAPO guide for more details. - [9/27/2025] FP8 Quantization in NeMo RL
- [9/25/2025] On-policy Distillation
- Student generates on-policy sequences and aligns logits to a larger teacher via KL, achieving near-larger-model quality at lower cost than RL. See On-policy Distillation.
- [12/1/2025] Release v0.4.0!
- First release with official NGC Container nvcr.io/nvidia/nemo-rl:v0.4.0.
- 📊 View the release run metrics on Google Colab to get a head start on your experimentation.
- [9/30/2025] Accelerated RL on GCP with NeMo RL!
- [8/15/2025] NeMo-RL: Journey of Optimizing Weight Transfer in Large MoE Models by 10x
- [7/31/2025] NeMo-RL V0.3: Scalable and Performant Post-training with Nemo-RL via Megatron-Core
-
[7/25/2025] Release v0.3.0!
- 📝 v0.3.0 Announcement
- 📊 View the release run metrics on Google Colab to get a head start on your experimentation.
-
[5/14/2025] Reproduce DeepscaleR with NeMo RL!
- [5/14/2025] Release v0.2.1!
- 📊 View the release run metrics on Google Colab to get a head start on your experimentation.
Overview
NeMo RL is an open-source post-training library under the NVIDIA NeMo Framework, designed to streamline and scale reinforcement learning methods for multimodal models (LLMs, VLMs etc.). Designed for flexibility, reproducibility, and scale, NeMo RL enables both small-scale experiments and massive multi-GPU, multi-node deployments for fast experimentation in research and production environments.
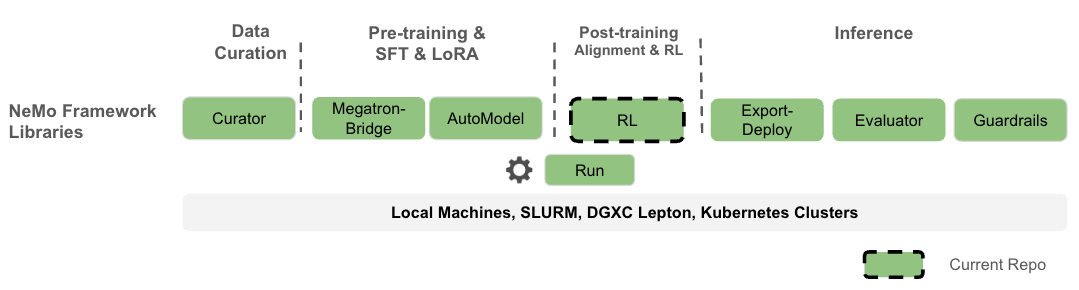
What you can expect: - Flexibility with a modular design that allows easy integration and customization. - Efficient resource management using Ray, enabling scalable and flexible deployment across different hardware configurations. - Hackable with native PyTorch-only paths for quick research prototypes. - High performance with Megatron Core, supporting various parallelism techniques for large models and large context lengths. - Seamless integration with Hugging Face for ease of use, allowing users to leverage a wide range of pre-trained models and tools. - Comprehensive documentation that is both detailed and user-friendly, with practical examples.
Please refer to our design documents for more details on the architecture and design philosophy.
Training Backends
NeMo RL supports multiple training backends to accommodate different model sizes and hardware configurations:
- DTensor - PyTorch's next-generation distributed training with improved memory efficiency (PyTorch-native TP, SP, PP, CP, and FSDP2).
- Megatron - NVIDIA's high-performance training framework for scaling to large models with 6D parallelisms.
The training backend is automatically determined based on your YAML configuration settings. For detailed information on backend selection, configuration, and examples, see the Training Backends documentation.
Generation Backends
NeMo RL supports multiple generation/rollout backends to accommodate different model sizes and hardware configurations:
- vLLM - A high-throughput and memory-efficient popular inference and serving engine.
- Megatron - A high-performance Megatron-native inference backend which eliminates weight conversion between training and inference.
For detailed information on backend selection, configuration, and examples, see the Generation Backends documentation.
Features
✅ Available now | 🔜 Coming in v0.6 - 🔜 Muon Optimizer - Emerging Optimizer support for SFT/RL - 🔜 Megatron Inference - Improved performance for Megatron Inference (avoid weight conversion). - 🔜 SGLang Inference - SGLang rollout support for optimized inference. - 🔜 Improved Native Performance - Improve training time for native PyTorch models. - 🔜 Improved Large MoE Performance - Improve Megatron Core training performance and generation performance. - 🔜 New Models - Qwen3-Next, Nemotron-Super. - 🔜 Expand Algorithms - GDPO, LoRA support for RL(GRPO) and DPO - 🔜 Resiliency - Fault tolerance and auto-scaling support - 🔜 On-Policy Distillation - Multi-teacher and cross tokenizer distillation support - 🔜 Speculative Decoding - Speculative Decoding support for rollout acceleration
- ✅ Distributed Training - Ray-based infrastructure.
- ✅ Environment Support and Isolation - Support for multi-environment training and dependency isolation between components.
- ✅ Worker Isolation - Process isolation between RL Actors (no worries about global state).
- ✅ Learning Algorithms - GRPO/GSPO/DAPO, SFT(with LoRA), DPO, and On-policy distillation.
- ✅ Multi-Turn RL - Multi-turn generation and training for RL with tool use, games, etc.
- ✅ Advanced Parallelism with DTensor - PyTorch FSDP2, TP, CP, and SP for efficient training (through NeMo AutoModel).
- ✅ Larger Model Support with Longer Sequences - Performant parallelisms with Megatron Core (TP/PP/CP/SP/EP/FSDP) (through NeMo Megatron Bridge).
- ✅ Sequence Packing - Sequence packing in both DTensor and Megatron Core for huge training performance gains.
- ✅ Fast Generation - vLLM backend for optimized inference.
- ✅ Hugging Face Integration - OOB support in the DTensor path, CKPT conversion available for Megatron path through Megatron Bridge middleware.
- ✅ End-to-End FP8 Low-Precision Training - Support for Megatron Core FP8 training and FP8 vLLM generation.
- ✅ Vision Language Models (VLM) - Support SFT and GRPO on VLMs.
- ✅ Megatron Inference - Megatron Inference for fast Day-0 support for new Megatron models (avoid weight conversion).
- ✅ Async RL - Support for asynchronous rollouts and replay buffers for off-policy training, and enable a fully asynchronous GRPO.
- ✅ Nemo-Gym Integration - RL Environment Integration.
- ✅ GB200 - container support for GB200.
Table of Contents
- Prerequisites
- Quick Start
-
Support Matrix
- Set Up Clusters
- Tips and Tricks
- Citation
- Contributing
- Licenses
Quick Start
Use this quick start to get going with either the native PyTorch DTensor or Megatron Core training backends.
[!NOTE] Both training backends are independent — you can install and use either one on its own.
For more examples and setup details, continue to the Prerequisites section.
| Native PyTorch (DTensor) | Megatron Core |
|---|---|
Clone and create the environment
NRL_FORCE_REBUILD_VENVS=true. See Tips and Tricks.
|
|
| Run GRP |